前置知识
简介
2017年谷歌在发表的论文中第一次推出了Transformer架构,直到现在,市面上大多数的LLM(Large Language Model,大语言模型)基本都在延用这套架构,只不过在谷歌的架构基础上做了不同程度的优化和改进。
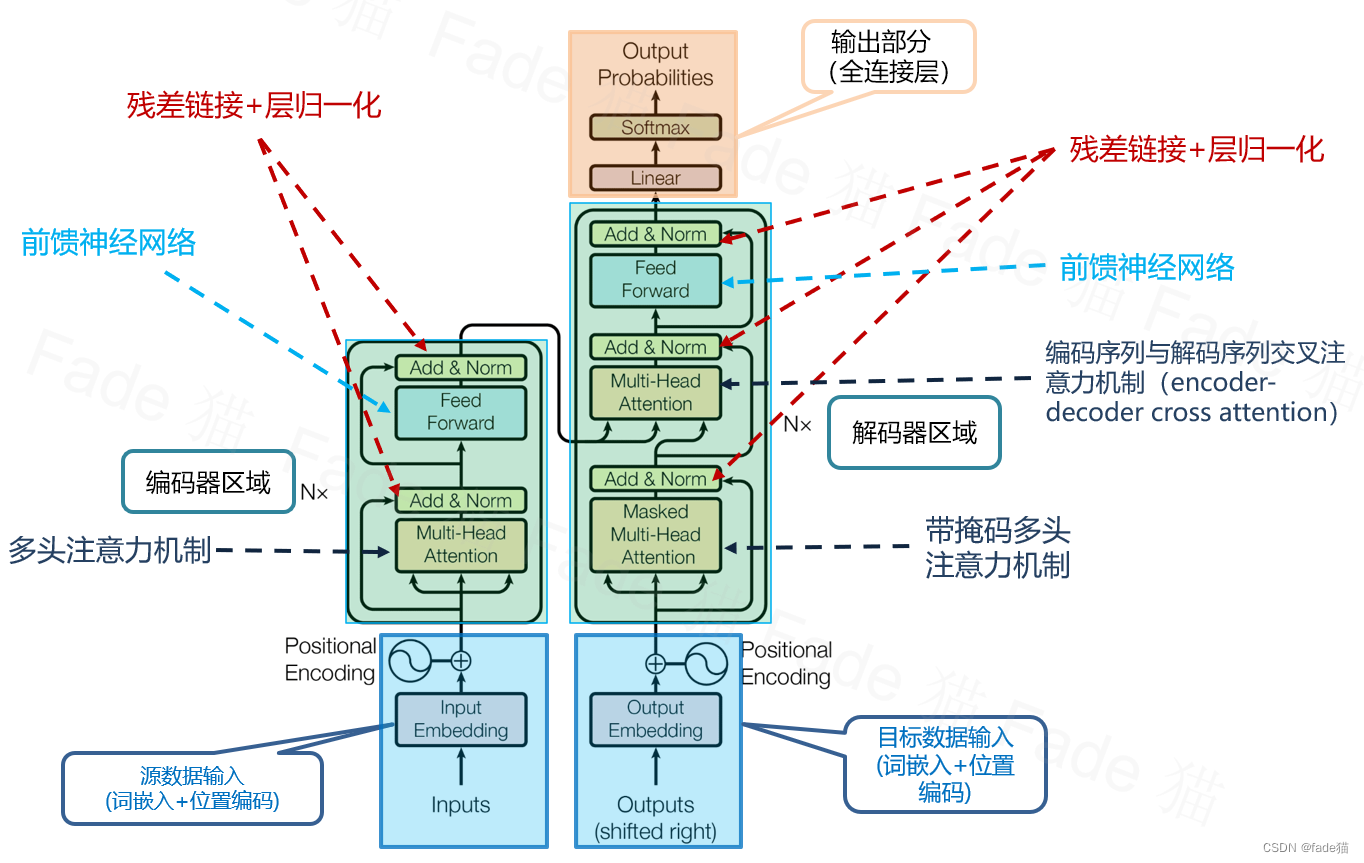
大概流程
Inputs -> Input Embedding + Position Encoding -> 模型的输入向量 -> Encoder -> Decoder -> 线性转换 -> Softmax
关键词
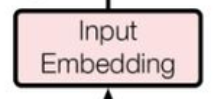
Input Embedding(词嵌入)
Position Encoding(位置编码)

Encoder(编码器)
Decoder(解码器)
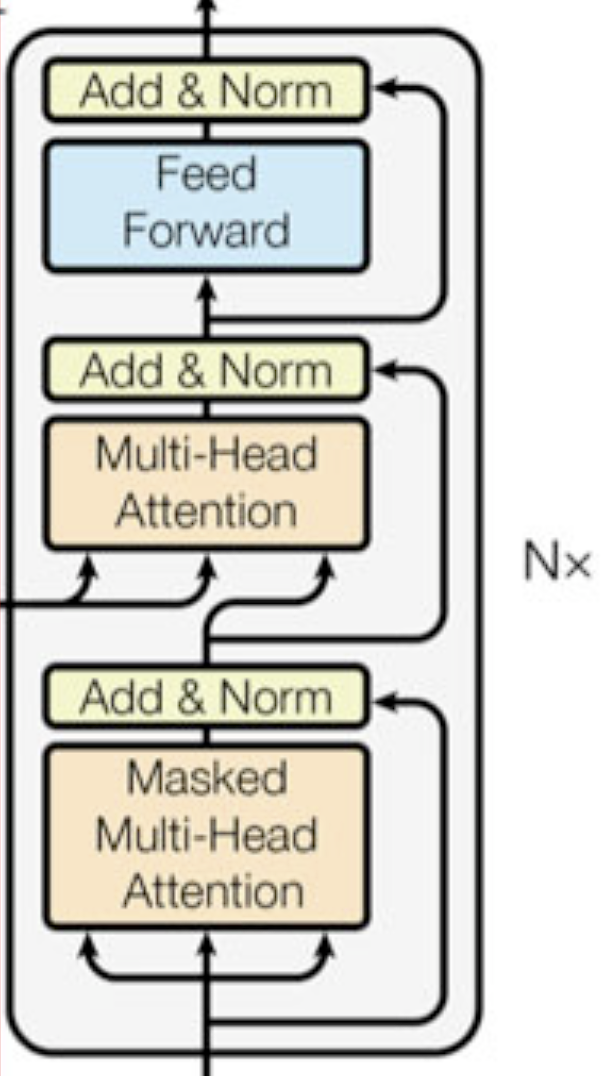
注意力机制(Attention):自注意力(Self-Attention)、多头注意力(Multi-Head Attention)、多头自注意力(Multi-Head Self-Attention)、带掩码的多头注意力(Marked Multi-Head Attention)、交叉注意力(Cross Attention)
多头注意力


带掩码的多头注意力


FFN(Feed-Forward Network,前馈网络)
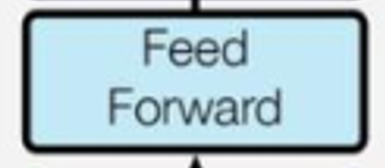

Add & Norm(残差连接和归一化)
Output Embedding & Position
作为解码器的每一层的输入向量,主要作用来自训练阶段,推理阶段则是将解码器上一层的输出拼接到最新的Output后面。
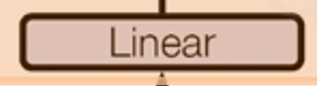
Linear(线性变换)

Softmax(比如模型词表有1000个字,就输出这1000个字对应的概率,并且这1000个概率值的总和是1,模型就会选择概率最大的那个字)


词嵌入+位置编码(Input)
这里因为是测试所以每个向量的维度只有5维,但是官方给出的是512维,而市面上的模型维数一般要更大一些。
词嵌入(Input Embedding)
这一步又分为了分词化(Tokenization)、词表映射以及将token id列表转换成向量三个步骤。
比如"I love China"这句话,在经过分词化和词表映射(采用词粒度分词策略)之后就得到:[35,364,87],一共分成了三个token,而这三个token又分别对应了三个向量(词表中的每个token都对应一个独一无二的向量),最终就得到了三个向量[4,9,0,1,4],[0,4,1,8,5],[3,5,0,8,7]
位置编码(Position Encoding)
位置向量,比如模型最大能输入500个字,那么就对应了500个位置向量(模型训练初始时位置向量都是随机的,但是每个位置向量全局唯一),这一步的目的是为了能让模型知道每个token在这个句子中的位置信息,因为模型内部是拿不到位置信息的,所以这一步必须要做而且是提前做。
比如第一个位置是[3,5,1,0,2],第二个位置是[6,2,3,5,3],第三个位置[9,2,3,6,1],然后拿第一个token的向量加上第一个位置的位置向量,拿第二个token的向量加上第二个位置的位置向量,拿第三个token的向量加上第三个位置的位置向量,以此类推。
由此得到的一串新的向量,将作为真正的模型输入交给模型处理
注意力机制(Attention)
注意力机制的核心离不开三个参数:Q(Query)、K(Key)、V(Value)。每个token在进行Attention运算时都会通过权重矩阵运算映射成三个向量,对应了这三个参数。
注意力机制常见的有两种,分别是标准Attention和Self-Attention(自注意力),自注意力是注意力机制中的一种特殊机制,区别在于Q、K、V参数从哪里来:
在标准Attention中,Q来自解码器,K和V来自编码器,比如中译英场景:生成英文单词"eat"时,去中文“吃”那个位置聚焦,即将注意力放到中文的上下文,而不是目标生成的英文的上下文语境中,因为两种语言的语法是不同的。
自注意力Self-Attention中,Q、K、V均来自自身的编码器/解码器,即自己跟自己算注意力,比如“他吃苹果”,让“吃”这个token去聚焦“他”和“苹果”两个token,分析吃的对象是什么,是谁再吃。
自注意力(Self-Attention)
Query:每个token都要去查看整个句子中的其他所有token,从而加深理解自己在上下文中的身份和作用,比如"he eat apple”这句话,"he"会分别查看"eat"和"apple","eat"会分别查看"he"和"apple","apple"会分别查看"he”和"eat”。当"apple"这个token在看到”eat"这个token时就能知道自己是被"eat”的对象,即受害者的身份;同理当”apple"看到”he"这个token时就知道了自己是被”谁"吃的,即受害施加者。所以说一个token需要主动去查询其他token,这就是Query的意义。
Key:有了查询者这个身份,就必然少不了被查询者,也就是每个token都有可能被其他token查询,Key的作用是给自身贴标签,用于给Query作匹配的。比如"eat"这个token的Key就包含动作的信息,"he"这个token就包含了主语的信息。当”eat"查询到”apple"的Key包含了受害者的标签时就知道自己应该更关注”apple"而不是”he",所以”eat"对”apple"的权重更高,而”he"次之。然后就会拿”apple"的Value更新自己的向量,从而使自己对”apple"的权重更大。
Value:每个token所表示的字/词本身包含了一些含义,比如苹果是一种水果,苹果也是一种植物,这些都是苹果这个token本身的含义,跟Key没有直接联系。Value的作用是,当查询者查询到自己和当前token的关联性更大时,就会调取这个token的Value向量,用以更新自己的向量。
Value的信息(含义)来源有两种:
比如Qwen3-671B这个模型的参数量有671B,所以该模型里的"apple”这个token所表示的向量本身就已经包含了水果、植物等含义,这是模型发布时就已经嵌入的信息,即模型嵌入层自带了静态知识。
一般编码器/解码器都是多层堆叠的结构,每层运算都会将上一层的结果作为当前层的输入。当处在第一层中,"apple”的向量只包含了模型本身自带的信息,也就是第一种;当处于第二层时,"apple”的向量不仅包含了模型自带的信息,还包含了第一层运算时"apple”从句子的其他token中获得的信息,第三层就包含了第一层和第二层,以此类推。而在每一层的Attention运算中,Value通过输入的token向量间接继承了前面所有层的向量信息。
如何理解Q/K/V三者的关系
打个比方就是,你去图书馆找AI相关的书籍,你作为查询者,具备了Query的身份;然后你会看到一系列的分区,比如历史、文学、机械、儿童读物、计算机等等,然后你检索到计算机这个标签包含了AI的含义,就会去计算机的分区找AI相关的书籍,这里AI书籍本身作为被查询者,同时也包含了计算机这个标签,这里体现了Key的作用;然后AI书籍又有本身的实际含义,比如人工智能、深度学习架构等等,这就体现了Value的作用。
又比如,你有一个同事,他刚来公司面试时,是作为面试者的身份,也就是被查询者(Key)的身份,然后入职之后,他就成为了公司的员工,此时他就包含了Value的身份,后来他成为了面试官,此时他就有了查阅面试者的能力,也就是Query的身份。
总而言之言而总之,同一个token会同时存在Q/K/V三个参数,因为每个token都同时拥有这三种身份。
多头注意力(Multi-Head Attention)
多头注意力是将一个高维度的向量拆成多个低维度的向量,然后让多个Attention并行运算。并不是单纯的将维度拆开,而是将一个向量通过矩阵运算映射成多个低维度的向量,每个低维度向量在各自的子空间计算注意力,每个子空间可以专注于特定的领域,用不同的方式方法学习token之间的关系,这样比直接对一个高维度的向量进行注意力计算时间更快,而且最后合并的效果也更强。
这有一点类似于:你把一个超高清摄像头换成多个不同空间角度的普通摄像头,每个普通摄像头虽然单张照片分辨率低一些,但处理速度快;多个角度同时拍摄之后融合,最终能得到比单张超高清照片更全面的空间信息(比如正面、侧面、背面),而且总计算负担更小。
不过需要区分的是,在实际的大模型中,多个低维度的向量不存在所谓的“分辨率”变低的情况,这里只是类比。
前馈神经网络层(FFN)
FFN是一种纯数学模型,这里不做详细介绍,简单来说就是:FFN会对每个token的向量独立做两次线性变换,中间夹着一个非线性激活函数(ReLU、GELU、GLU等),即线性变换 + 非线性激活函数 + 线性变换。
这种数学模型的本意是为了能让模型学习到线性变换无法实现的复杂模式,因为如果没有非线性运算,那么多层的线性运算叠加,大模型本质上就是一个超大型的线性模型,堆再多的参数提升都很有限。
然而近些年研究证实了这种数学模型能记住静态知识。整个FFN的计算过程(线性变换 --> 激活 --> 线性变换) 被证实是一种Key-Value的模式匹配,相当于是存储了大量的模式-特征对(宏观表现上类似于问题-答案对,相当于存储了大量知识)。当输入的token向量的权重达到某个临界值,FFN中的某些通路就会被激活,而最后的线性变换就能将激活的知识转换成向量进行输出。
这正是大语言模型能够在不联网的情况下回答一些基础知识的原因,这些知识都是模型在训练过程中记录在FFN中的。
“整个 FFN 的计算过程(第一层线性变换 → 激活 → 第二层线性变换)可以被解释为一次 Key-Value 检索:第一层线性变换将输入与存储的 Key 做匹配,激活函数选出匹配上的 Key,第二层线性变换则输出对应的 Value。”
编码器和解码器
编码器和解码器都包含了注意力层、前馈网络层以及残差连接和归一化等核心组成部分,但是他们在功能上是截然不同的。
编码器(Encoder)
编码器的目的是为了让模型先将用户输入的信息完完整整的理解一遍,包括每个token与其他所有token相互之间的权重、语义、上下文关系等等
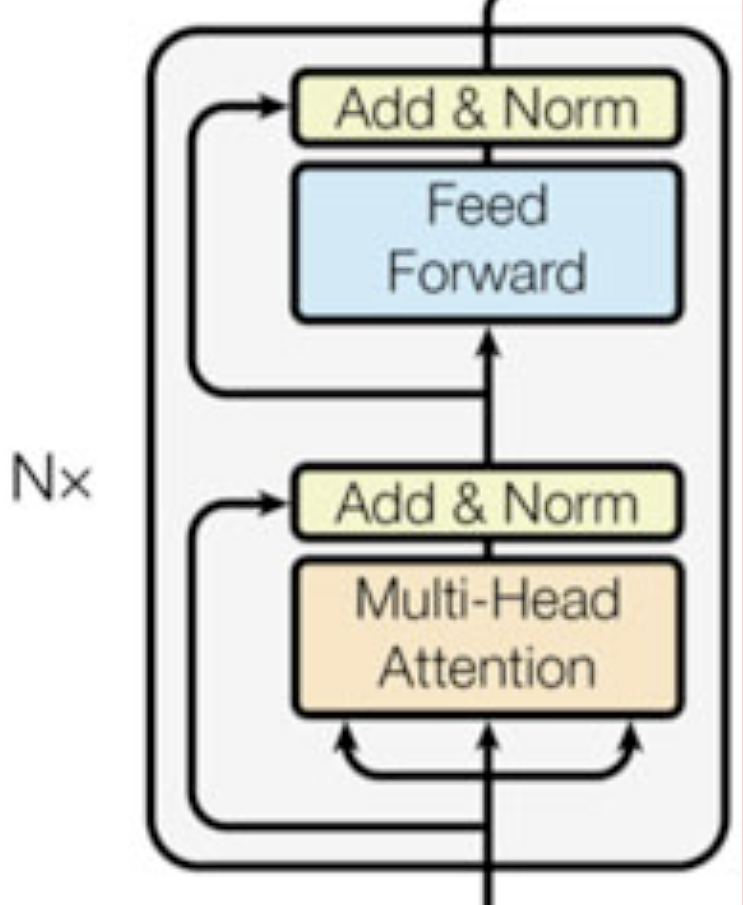
从图中可以大致看出编码器的工作流程(自下而上):多头注意力层 -> 残差连接&归一化 -> 前馈网络(知识检索) -> 残差连接&归一化。
最左侧的Nx代表编码层是一个多层堆叠的结构,即编码层的运算会持续N次,并且每次编码层的输出都会作为下一层运算的输入。
你可能会疑问,编码器既然是对用户输入信息进行理解,为什么还需要通过前馈网络检索知识?其实这是因为编码器的FFN并不是要检索出句子的后续内容,即所谓的成语接龙,而是通过FFN从海量知识中带出和用户输入信息高度匹配的信息,融合到编码器输出的向量中。这使得编码器最后输出的一组向量能包含更加丰富全面的信息。
解码器(Decoder)
解码器要比编码器要更复杂一些,首先来看一下解码器的大致结构:
自下而上来看就是:带掩码的多头注意力层 --> 残差连接 & 归一化 --> 交叉注意力层(Cross Attention) ,其中交叉注意力层的结构为:多头注意力层 --> 残差连接 & 归一化 --> 前馈网络 --> 残差连接 & 归一化。
最右侧的Nx代表解码层是一个多层堆叠的结构,即解码层的运算会持续N次,并且每次解码层的输出都会作为下一层运算的输入。
这里有两个新东西,分别是带掩码的多头注意力层和交叉注意力层,这里先讲带掩码的多头注意力层:
什么是掩码呢?首先我们需要知道编码层(Encoder)的目的是理解用户输入,那么解码层(Decoder)的目的就是推理用户的问题和意图。所以注意力层在推理的过程中,只能是第一次看到第1个Token,第二次看到第1个Token和第2个Token,第三次看到第1、2、3个Token,以此类推。这就需要手动创建掩码矩阵,假如用户输入了5个字,被分词成五个token,那么掩码矩阵大概长这样:
[True, False, False, False, False]
[True, True, False, False, False]
[True, True, True, False, False]
[True, True, True, True, False]
[True, True, True, True, True]只有当当前token对应掩码是True时,注意力层才能看到这个token,否则就看不到。否则后面的Token反而可能会干扰到注意力运算,因为这是推理过程,所以必须遵循因果,即先来后到。
因此上面的掩码矩阵专业术语就叫做因果掩码机制。
这就是带掩码的注意力层,至于多头注意力,就是按照之前所说的将一次高维度向量的运算映射成多个低维度向量的子运算,最后再融合成一个原始维度的向量,这里不做赘述。
交叉注意力
那么交叉注意力又是什么意思呢?
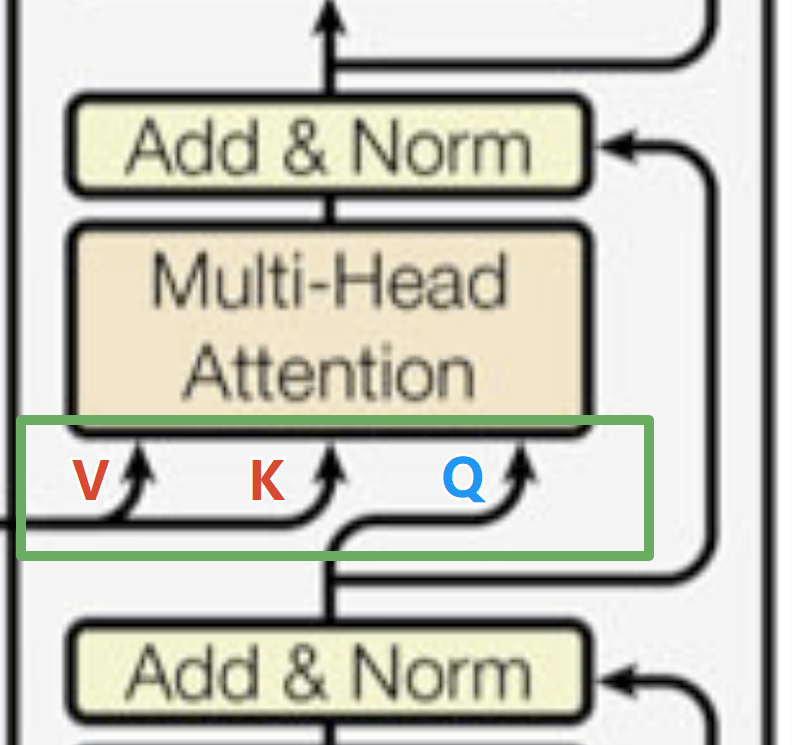
我们来看一下在掩码注意力层的上方,这里出现了三个箭头,最右侧的Q来自当前解码层的上一层输出,而最左侧的K和V均来自编码层,这就是“交叉”二字的含义:解码器在推理时不仅会参考当前解码器推理的上下文,还会参考编码层运算的结果,这种交叉注意力机制能够保证解码器是在理解用户输入的完整语义的情况下进行推理,而不是在自己的世界里瞎编。
总结就是,解码器每次运算经过交叉注意力层时都会拿着当前层掌握的推理信息和编码器的最终结果进行结合,然后再进行一次Attention运算,确保模型不是在自己的世界里瞎编。
词嵌入+位置编码(Output)
在解码器的下方又出现了词嵌入和位置编码,他们作为解码器的每一层的输入向量,在原理上和之前的Input Embedding/Position Encoding是一样的,只不过他们的作用主要体现在训练模型阶段。
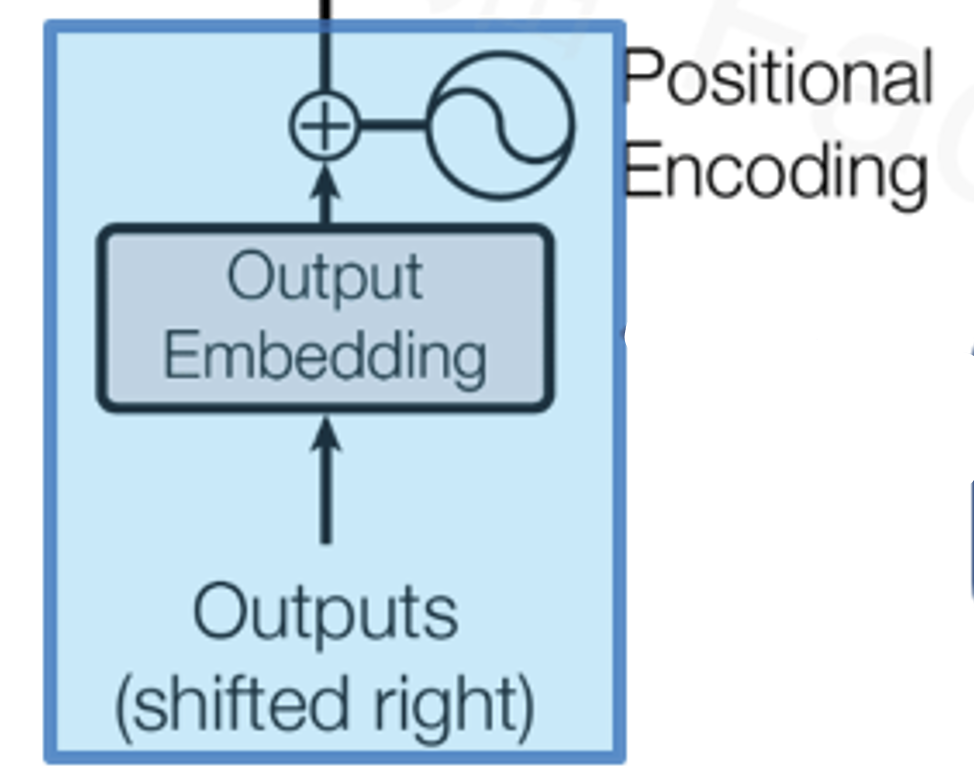
在训练模型时,我们会准备很多的问题和答案,让模型对照答案进行训练,这里的Outputs就是我们的答案了,然后跟Inputs一样,计算词嵌入和位置编码,同时配合因果掩码机制,让模型循环的完成每个位置的预测,这里有一点涉及到上一篇文章中讲到的模型训练知识:
SFT(监督微调)阶段的模型会学习大量的人类语料,特别是非常专业的垂直领域知识。学习完成之后,模型就能根据人类的意图来回答专业领域的问题。
这里的语料其实就是大量的问题-答案对,这样模型学到的才是真正有用的东西。
那么问题来了,推理阶段的Outputs是从哪里来的呢?
Outputs的组成主要分为以下几个步骤:
初始时,只给一个起始符
<sos>(StartOfSentence)。模型预测出第一个词(比如
I)。把
I拼到输入末尾,成为[<sos>, I]。用这个作为解码器输入,预测第二个词
love。重复,直到生成结束符
<eos>。
简单来说就是将解码器的上一层输出拼接到最新的Outputs之后,作为解码器下一层的输入,第一个字符用<sos>表示。
线性变换与Softmax
TODO
流程梳理
TODO
拓展
MoE混合专家模型:在本质上还是延用的Transformer架构,只是对原有的FFN层进行大刀阔斧的"手术"。原本的FFN是将所有的参数都放在一个大的模型里,而混合专家模型就是将一个大的拆分成多个小的,每个小的负责各自的领域,比如有的负责数学,有的负责历史,有的负责科学等等,这样在检索知识的时候,只会有部分专家的参数会被激活(可以想象成是大脑中的部分神经元和神经通路),而其他专家都不会被激活,这样在效率上有了很大提升。
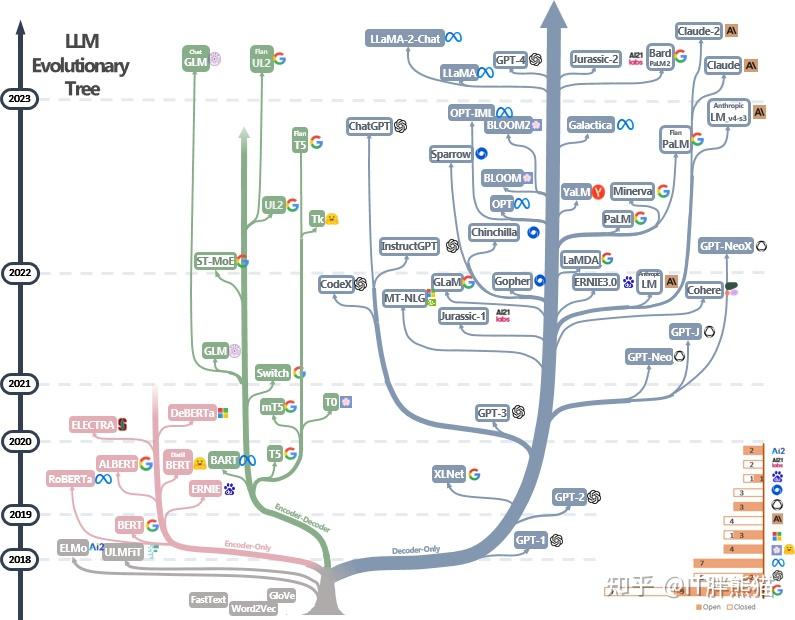
发展史
Transformer的发展史,分别对应图中的三个主要分支:Encoder-Only、Encoder-Decoder、Decoder-Only